Bayangkan Anda mempekerjakan seorang analis bisnis yang sangat brilian — lulusan terbaik dari universitas ternama, kemampuan analisis luar biasa, bisa memproses ribuan variabel sekaligus dan menghasilkan rekomendasi dalam hitungan detik.
Lalu Anda memberinya data yang salah.
Angka-angka yang tidak akurat. Laporan yang tidak lengkap. Informasi yang sudah usang berbulan-bulan. Tidak peduli seberapa cemerlang analis itu — rekomendasinya akan salah. Bukan karena ia tidak kompeten, tapi karena bahan bakunya bermasalah sejak awal.
Itulah persis cara kerja AI.
Semua pembicaraan tentang model AI yang semakin canggih, algoritma yang semakin pintar, dan kemampuan yang semakin mendekati manusia — semuanya runtuh jika fondasi datanya buruk. Dan fondasi itu, di dunia industri dan bisnis nyata, dimulai jauh sebelum AI itu sendiri hadir.
Mengapa Kita Sering Salah Memulai
Ada sebuah pola yang berulang dalam gelombang adopsi teknologi: kita terpesona pada lapisan paling atas — yang paling terlihat, paling dramatis, paling banyak diberitakan — dan melupakan bahwa ia berdiri di atas lapisan-lapisan yang lebih dalam.
Ketika internet mulai populer, semua orang berlomba membuat website — tanpa memahami infrastruktur jaringan yang memungkinkannya. Ketika cloud computing naik daun, semua orang ingin "pindah ke cloud" — tanpa membenahi arsitektur data mereka terlebih dulu.
Hari ini, pola yang sama berulang dengan AI.
Semua orang ingin mengimplementasikan AI. Semua orang ingin dashboard yang cerdas, predictive analytics yang akurat, sistem yang bisa merekomendasikan keputusan secara otomatis. Tapi ketika ditanya: "Data Anda seperti apa? Dari mana asalnya? Seberapa akurat dan seberapa sering diperbarui?" — jawabannya sering kali mengkhawatirkan.
Tiga Lapisan yang Harus Dipahami Bersama
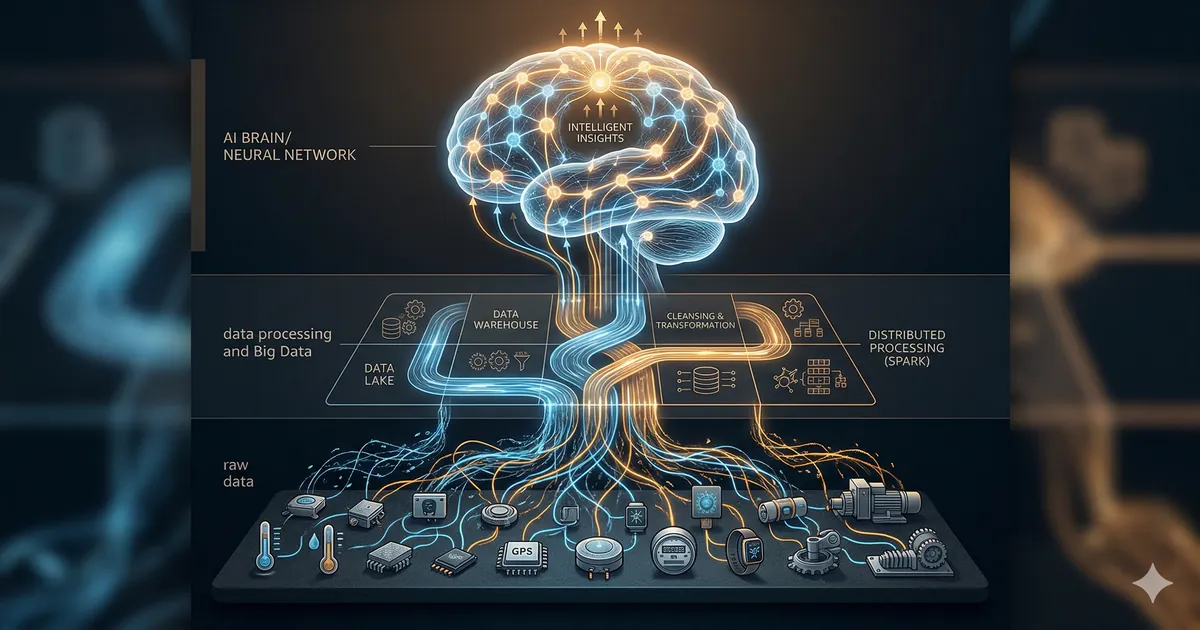
Untuk memahami mengapa AI tidak bisa berdiri sendiri, kita perlu melihat tiga lapisan yang sebenarnya bekerja bersama — dan peran unik yang dimainkan masing-masing.
Lapisan 1: IoT — Telinga dan Mata di Dunia Nyata
Internet of Things (IoT) adalah jaringan sensor dan perangkat yang terhubung ke internet — termometer digital di ruang server, sensor getaran di mesin pabrik, GPS di kendaraan logistik, kamera dengan kemampuan analisis visual di area produksi.
Peran IoT dalam ekosistem ini sangat fundamental: mengubah dunia fisik menjadi data digital, secara real-time dan berkelanjutan.
Analoginya: jika AI adalah otak, maka IoT adalah indera. Mata yang melihat, telinga yang mendengar, kulit yang merasakan. Tanpa indera yang berfungsi baik, otak yang paling cerdas pun tidak bisa membuat keputusan yang akurat tentang dunia di sekitarnya.
Data Siluman: Harta Karun yang Selama Ini Tidak Terlihat
Ada satu realita yang jarang dibicarakan secara terbuka di kalangan industri Indonesia: sebagian besar perusahaan sebenarnya sudah menghasilkan data yang sangat berharga setiap harinya — tapi tidak pernah menangkapnya. Bukan karena tidak mau. Tapi karena tidak ada sistem yang mendengarkan.
Saya menyebut ini data siluman — informasi yang secara fisik sudah ada di lapangan, terjadi setiap detik, tapi menguap begitu saja karena tidak ada sensor yang mencatatnya. Beberapa contoh yang paling umum ditemukan di industri:
Di lantai produksi manufaktur: Getaran mikro pada bearing mesin yang menandakan keausan sebenarnya sudah bisa terdeteksi 2–3 minggu sebelum mesin benar-benar rusak. Tapi karena tidak ada sensor getaran yang terpasang, tanda-tanda itu tidak pernah tertangkap. Yang terjadi kemudian adalah breakdown mendadak di tengah jadwal produksi — yang oleh banyak manajer dianggap "tiba-tiba", padahal mesinnya sudah "berbisik" berminggu-minggu sebelumnya.
Di area pertambangan: Jam idle alat berat — waktu di mana mesin menyala tapi tidak produktif — adalah salah satu pemborosan terbesar yang paling sulit dideteksi tanpa IoT. Data GPS dan sensor engine load yang jujur sering menunjukkan bahwa 20–30% waktu operasional sebenarnya dihabiskan dalam kondisi idle yang bisa dihindari.
Di fasilitas logistik dan cold storage: Berapa kali suhu cold storage keluar dari rentang optimal, dan pada jam berapa? Data-data ini secara langsung mempengaruhi kualitas produk dan biaya operasional — tapi di sebagian besar fasilitas, ia hanya dicatat jika ada insiden yang terlihat jelas.
Yang membuat data siluman ini begitu berharga bukan hanya bahwa ia ada — tapi bahwa ia sudah ada di sana sejak lama, menunggu untuk didengar. Dan baru setelah data ini berhasil ditangkap melalui pipeline Big Data yang solid — AI bisa mulai mengubahnya menjadi keputusan yang benar-benar bermakna.
Lapisan 2: Big Data — Jembatan yang Sering Dilupakan
Di sinilah lapisan yang paling sering dilewati dalam percakapan tentang AI — dan ironisnya, lapisan yang paling menentukan kualitas output.
Data mentah dari sensor IoT, dalam kondisi aslinya, hampir tidak berguna untuk AI. Ia berantakan, redundan, penuh noise, dan tidak terstruktur. Big Data adalah lapisan yang mengurus semua itu: menyimpan volume data yang masif, membersihkannya dari noise dan error, mengorganisirnya dalam struktur yang bisa dipahami AI, dan memastikan ia tersedia ketika dibutuhkan.
Bayangkan Big Data sebagai sistem pengolahan air. Air hujan yang jatuh dari langit (data mentah dari IoT) tidak langsung bisa diminum. Ia perlu dikumpulkan, disaring, dimurnikan, dan didistribusikan (Big Data) sebelum bisa dimanfaatkan (AI). Kualitas air yang diminum sangat bergantung pada kualitas sistem pengolahannya — bukan hanya pada seberapa banyak hujan yang turun.
Organisasi yang melewati tahap ini — langsung dari "kami punya banyak sensor" ke "kami mau implementasi AI" — hampir selalu berakhir dengan sistem AI yang memberikan rekomendasi yang tidak bisa dipercaya. Bukan karena AI-nya buruk, tapi karena airnya belum diolah.
Lapisan 3: AI — Yang Berpikir di Atas Fondasi yang Sudah Dibangun
Barulah di lapisan ketiga ini AI masuk — menganalisis data yang sudah bersih dan terstruktur, menemukan pola yang tidak terlihat oleh mata manusia, dan menghasilkan insight atau keputusan yang actionable.
Di sinilah keajaiban yang sering diberitakan terjadi: mesin yang memprediksi kerusakannya sendiri sebelum terjadi, sistem yang mengoptimalkan konsumsi energi secara dinamis, algoritma yang merekomendasikan penyesuaian proses produksi berdasarkan kombinasi puluhan variabel sekaligus.
Tapi semua ini hanya mungkin karena dua lapisan sebelumnya sudah bekerja dengan benar.
Pertanyaan yang Lebih Penting dari "AI Apa yang Harus Kita Pakai?"
Ketika seorang eksekutif atau manajer mulai mempertimbangkan implementasi AI, pertanyaan pertama yang sering muncul adalah tentang tools: "Model AI apa yang terbaik? Vendor mana yang harus dipilih? Platform apa yang paling canggih?"
Pertanyaan-pertanyaan itu penting — tapi bukan yang paling penting. Pertanyaan yang seharusnya diajukan lebih dulu:
"Data apa yang kami punya, dari mana asalnya, dan seberapa bisa dipercaya?"
Jika jawabannya adalah "kami mengumpulkan data secara manual di spreadsheet", atau "sensor kami sudah terpasang tapi datanya jarang dilihat", atau "kami tidak yakin seberapa akurat pembacaan alat kami" — maka ini adalah sinyal bahwa fondasi perlu dibenahi sebelum AI diundang masuk.
Ini bukan kabar buruk. Ini adalah peta jalan yang jelas: benahi IoT-nya dulu, bangun pipeline Big Data yang solid, baru AI akan bisa bekerja seperti yang dijanjikan. Seperti yang pernah saya tulis tentang panduan IoT untuk manufaktur Indonesia — urutan implementasi menentukan segalanya.
Penutup: Urutan Itu Penting
Ada sebuah prinsip dalam memasak yang relevan di sini: hidangan yang luar biasa dimulai dari bahan baku yang baik. Teknik memasak yang sempurna tidak akan menyelamatkan bahan baku yang sudah basi.
AI adalah teknik memasaknya. IoT dan Big Data adalah bahan bakunya.
Investasi terbesar dan terpenting dalam perjalanan transformasi digital bukan pada AI yang paling canggih — tapi pada fondasi data yang paling dapat dipercaya. Karena pada akhirnya, AI Anda hanya akan secerdas data yang diterimanya.
Dan data yang baik tidak jatuh dari langit. Ia dibangun, dirawat, dan dijaga kualitasnya — setiap hari, di lapangan, jauh sebelum algoritma pertama dijalankan.